前回はBeautifulSoupを使ったWebスクレイピングを行いましたが、JavaScriptで動くページ等の場合はBeautifulSoupではスクレイピングに失敗する場合が多々あります。それは「BeautifulSoupでダウンロードしたHTML」と「ブラウザに実際に表示されるHTML」が異なるからです。「ブラウザに実際に表示されるHTML」を取得するためには、「ブラウザに実際に表示」しなければなりません。そこでSeleniumを使用したWebスクレイピングを使います。
ターゲットの分析
前回に続き、ヤフーファイナンスから米ドルの為替レートをスクレイピングしたいと思う。前回BeautifulSoupでスクレイピングできていることからわかる通り、あえてSeleniumを使う必要はないのだが、BeautifulSoupの場合との比較のために今回もヤフーファイナンスの米ドルの為替レートを対象とする。
https://info.finance.yahoo.co.jp/fx/convert/
「最新取引レート」の「142.550000」が今回スクレイピングしたい情報とする。右クリックして「検証」を押すと、ソースコードが右上に表示される。「<td class=”newest”>」を右クリックし「Copy XPath」または「Copy full XPath」をクリックする。
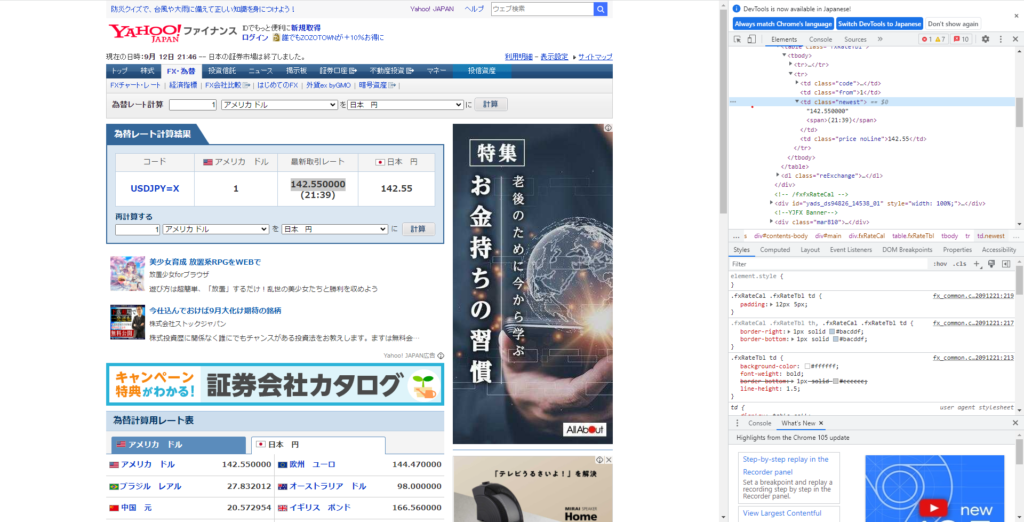
「Copy XPath」の場合は、
//*[@id="main"]/div[1]/table/tbody/tr[2]/td[3]「Copy full XPath」の場合は、
/html/body/div[1]/div[2]/div[2]/div[1]/div[1]/table/tbody/tr[2]/td[3]が、クリップボードにコピーされる。これらが「<td class=”newest”>」から「</td>」タグの範囲を指す。
ヘッドレスブラウザの準備
冒頭で「ブラウザに実際に表示」しなければならないと述べました。つまりSeleniumはブラウザを制御しますが、Seleniumで制御される側のブラウザを用意しなければなりません。今回はChromeがインストールされたPCを用いているので、ChromeDriverを使います。
まずChromeのバージョンを調べます。Chromeの「ヘルプ」→「Google Chromeについて」を開きます。「バージョン: 105.0.5195.102(Official Build) (64 ビット)」でした。
つまりメジャーバージョンは105ですので、下記サイトで対応するChromeDriverは「If you are using Chrome version 105, please download ChromeDriver 105.0.5195.52」と判断します。
https://chromedriver.chromium.org/downloads
解答したChromedriver.exeは、例として
C:/chromedriver_win32_v105/chromedriver.exeに配置します。
Seleniumを使ったスクレイピング
まず、ライブラリをインポートする。インストールしてない場合はpipでインストールする。
from selenium import webdriver次に、変数urlを定義し、スクレイピングしたいWEBサイトのアドレスを渡す
target_url = 'https://info.finance.yahoo.co.jp/fx/convert/'chromedriver.exeの置き場所を指定する。
webdriver_path="C:/chromedriver_win32_v105/chromedriver.exe"冒頭で取得したXPathを指定する。
full_xpath = '/html/body/div[1]/div[2]/div[2]/div[1]/div[1]/table/tbody/tr[2]/td[3]'chromedriver.exeを読み込む。ここでChromedriverの画面が開くので注意。
driver = webdriver.Chrome(webdriver_path)Webサイトにアクセスする。
driver.get(target_url)ページのソースを取得する。
driver.page_sourceページの「最新取引レート」の要素を取得する。
newest_rate = driver.find_element_by_xpath(full_xpath)find_element_by_xpathからtext要素のみ取り出す。
newest_rate = newest_rate.text表示する。
print(str(newest_rate))実行結果
142.520000
(22:10)このように、レートと時刻が2行にわたって表示される。
不要な行を取り除く
2行目(時刻)は消して1行目(レート)だけ取り出したい。まずは取得した内容を改行コードで分割した配列として表示する。
print(newest_rate.splitlines())実行結果
['142.520000', '(22:10)']これで配列の1つ目の要素にレート、2つ目の要素に時刻が代入された。
この配列の1つ目の要素だけ表示すればよい。
newest_rate_matrix = newest_rate.splitlines()
print(str(newest_rate_matrix[0]))実行結果
142.520000Chromedriverを閉じる
以上でスクレイピング自体はできるのだが、最後にChromedriverを明示的に閉じないと開きっぱなしになる。
driver.close()まとめ
まとめると、以下のソースコードとなる。
from selenium import webdriver
# 変数urlを定義し、スクレイピングしたいWEBサイトのアドレスを渡す
target_url = 'https://info.finance.yahoo.co.jp/fx/convert/'
# chromedriver.exeの置き場所
webdriver_path="C:/chromedriver_win32_v105/chromedriver.exe"
# xpathの定義
full_xpath = '/html/body/div[1]/div[2]/div[2]/div[1]/div[1]/table/tbody/tr[2]/td[3]'
# chromedriver.exeの読み込み
driver = webdriver.Chrome(webdriver_path)
# Webサイトにアクセスする
driver.get(target_url)
# ページのソースを取得する
driver.page_source
# ページの「最新取引レート」の要素を取得する
newest_rate = driver.find_element_by_xpath(full_xpath) # xpathでの指定
# find_element_by_xpathからtext要素のみ取り出す
newest_rate = newest_rate.text
# 取得した内容を改行コードで分割した配列に代入する
newest_rate_matrix = newest_rate.splitlines()
# 配列の0番目の要素を表示する
print(str(newest_rate_matrix[0]))
# ヘッドレスブラウザを閉じる
driver.close()GitHubは下記の通り。
https://github.com/catalyst-yuki-k/python_sample/blob/main/web_scraping/selenium_sample.py
次回もSeleniumについて書きたいと思います。