Python使ってWebスクレイピングを数年ぐらい続けており、大概のものはスクレイピングできるようになったのだが、各目的のソースコードが膨大な行数になってきて本質部分が何だったかわからなくなってきたので、備忘録がてら基本だけまとめておきたいと思う。
ターゲットの分析
いきなり話がそれるが、例題に用いるターゲットの選定に結構苦労した。やろうと思えばなんでもスクレイピングできるのだけども、玉ねぎの皮を剥くがごとく何度も何度も処理しないと欲しい文字列等が出てこないサイトが多いため、教科書的なサイトは限られる。
今回はヤフーファイナンスから米ドルの為替レートをスクレイピングしたいと思う。
https://info.finance.yahoo.co.jp/fx/convert/
「最新取引レート」の「142.550000」が今回スクレイピングしたい情報とする。右クリックして「検証」を押すと、ソースコードが右上に表示される。「<td class=”newest”>」から「<td>」で囲まれていることが分かる。
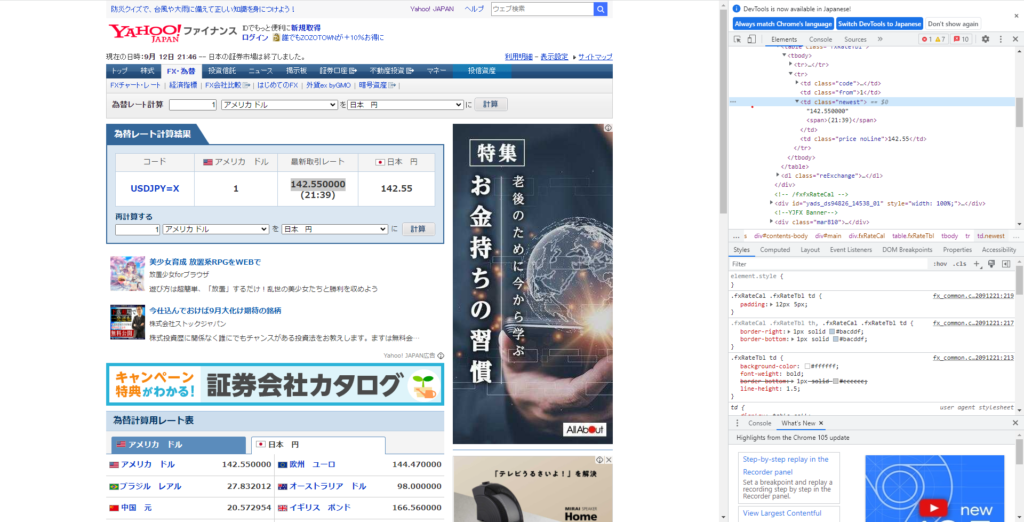
BeautifulSoupを使ったスクレイピング
まず、ライブラリをインポートする。インストールしてない場合はpipでインストールする。requestsはHTTP通信のライブラリ、bs4(beautifulsoup)はHTMLおよびXMLドキュメントを解析(Webスクレイピング)するためのライブラリである。
import requests
import bs4次に、変数urlを定義し、スクレイピングしたいWEBサイトのアドレスを渡す
target_url = 'https://info.finance.yahoo.co.jp/fx/convert/'requests.get()に対してurlを渡す。requests.get()で指定されたwebの情報を取得し、結果を変数target_resに格納する。
target_res = requests.get(target_url)Responseオブジェクトのステータスコードが200番台以外の場合は例外処理する(エラーメッセージを表示し、スクリプトを停止する)この行は無くても動くが、あったほうがエラーを分析しやすくなる。
target_res.raise_for_status()HTML文字列からBeautifulSoupオブジェクトを生成する
target_soup = bs4.BeautifulSoup(target_res.text, "html.parser")タグ「td」クラス「newest」の要素を取得する
newest_rate = target_soup.find("td", class_="newest")取得した内容を表示する
print(str(newest_rate))実行結果
<td class="newest">142.520000<span>(22:10)</span></td>このように、タグと本文全てが表示される。
不要なタグを取り除く
タグは消して中身だけ取り出したい。そんな場合はget_text()を使う。以下の行だけ末尾に「.get_text()」を書き加える。
newest_rate = target_soup.find("td", class_="newest").get_text()実行結果
142.520000(22:10)不要な要素を取り除く
「(22:10)」は時刻を意味しているが、この文字列を取り除きたいとする。ソースコードを分析すると、「<td>」タグ内にすべてが入っており、さらにこの時刻は「<span>」タグ内に入っている。つまり、「<span>」タグの情報を除去すればよい。
for tag in target_soup.findAll(["span"]):
tag.decompose()実行結果
142.520000まとめ
まとめると、以下のソースコードとなる。
import requests
import bs4
# 変数urlを定義し、スクレイピングしたいWEBサイトのアドレスを渡す
target_url = 'https://info.finance.yahoo.co.jp/fx/convert/'
# requests.get()に対してurlを渡す
# requests.get()で指定されたwebの情報を取得し、結果を変数target_resに格納する
target_res = requests.get(target_url)
# Responseオブジェクトのステータスコードが200番台以外の場合は例外処理する
# (エラーメッセージを表示し、スクリプトを停止する)
target_res.raise_for_status()
# HTML文字列からBeautifulSoupオブジェクトを生成する
target_soup = bs4.BeautifulSoup(target_res.text, "html.parser")
# span要素を取り除く
for tag in target_soup.findAll(["span"]):
# タグとその内容の削除
tag.decompose()
# <td class="newest">の要素を取得する
newest_rate = target_soup.find("td", class_="newest").get_text()
# 取得した内容を表示する
print(str(newest_rate))GitHubは下記の通り。
https://github.com/catalyst-yuki-k/python_sample/blob/main/web_scraping/beautifulsoup_sample.py
次回はSeleniumを使ったスクレイピングについて書きたいと思います。